
Description and Motivation
The plebiscite about the peace agreements of Colombia in 2016 was the mecanism of endorsement to aprove the agreements between the Colombia’s goberment and the “Fuerzas Armadas Revolucionarias de Colombia” (FARC). The voting was scheduled for Sunday, October 2, 2016.
This was the question made in the plebiscite:
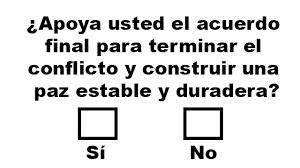
Given the preceding introduction, the current project aims to use Python scraping tools to retrieve information at the municipal and departmental levels, and then create a dashboard in Google Data Studio using the findings.
Methodologies
The Scraping process of the Registraduría Nacional has the following functions:
- Making the scraping of the principal page about the scrutiny of the votation results the previous action is to extract the access link to each Colombia’s department in the votation. Later, extracting the information by department, we extract each one of the municipal links related to that department.
- We make the scraping of each municipal page to extract the votation results such as the participation percentage and plebiscite approval.
In this project, we extract the information the 1.186 municipals by 34 departments (including consulates and Bogota D.C.).
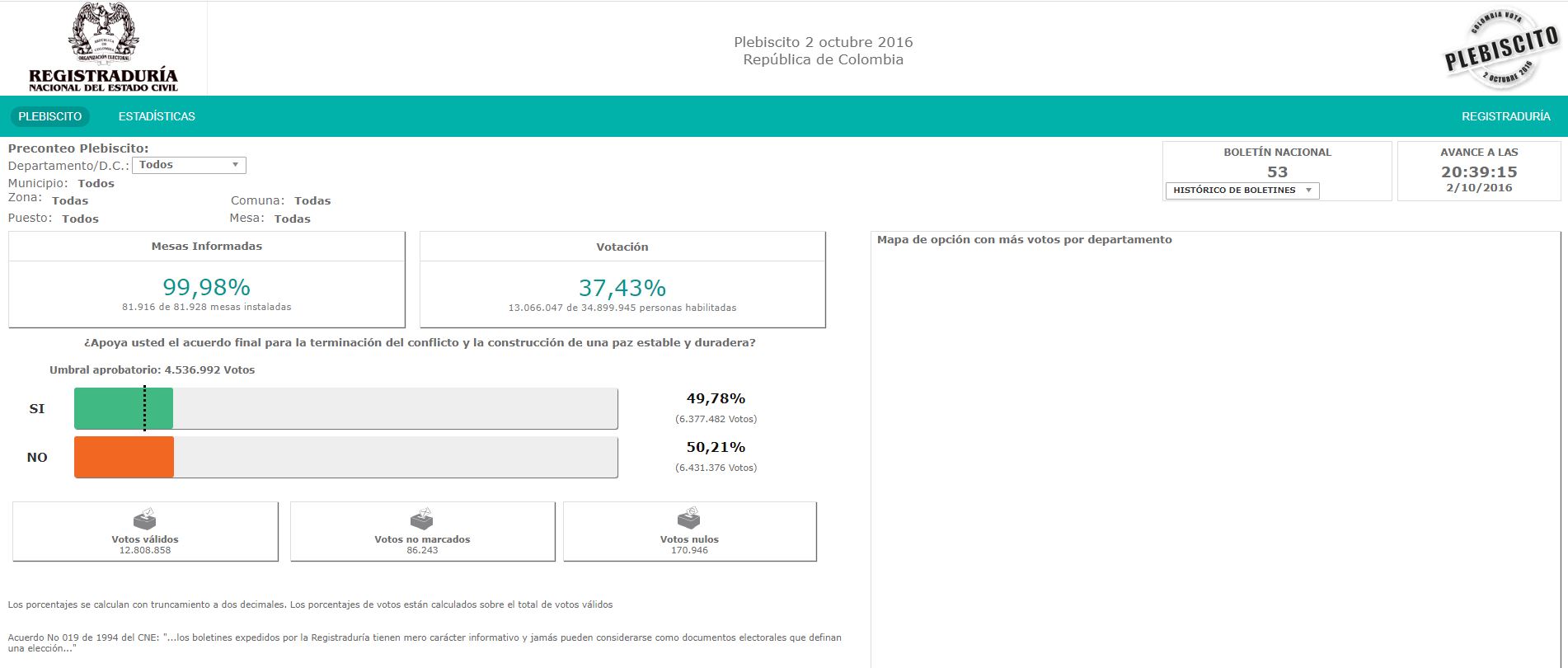
- After we extract the information, we generate a Dashboard in Google Data Studio. The following visualization is the dashboard which is the result of the scrapping.
Scraping process
We begin importing the libraries needed for the manipulation of the databases and the extraction in the website. For that purpose, we use pandas, BeautifulSoup y requests, as we show in the following code:
1
2
3
4
5
6
7
8
import re
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import warnings
from requests.packages.urllib3.exceptions import InsecureRequestWarning
warnings.simplefilter('ignore',InsecureRequestWarning)
Once we imported the libraries, with the library calls request, we call the code of the website intending to find out the link with the result information of the plebiscite by the department.
1
2
3
4
5
6
html = requests.get("https://elecciones.registraduria.gov.co/pre_plebis_2016/99PL/DPLZZZZZZZZZZZZZZZZZ_L1.htm", verify=False).text
# estructurar datos a partir de archivos HTML
soup = BeautifulSoup(html, "lxml")
depa=re.findall('<a href="../99PL/DP["\w\s.>]+', str(soup))[2:-1]
departamentos=pd.DataFrame()
departamentos['link1']=depa
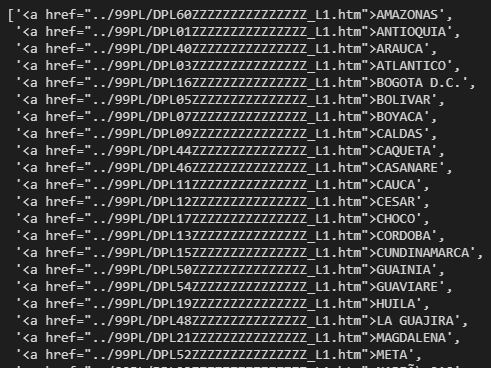
Later, with the links list by department, we perform a data cleaning to generate the inputs. The inputs will be the resource to the second scraping by municipal level.
1
2
3
departamentos['link']=departamentos['link1'].map(lambda x:x.replace('<a href="../', '').replace("</a></li>", "").replace('">', ",")).map(lambda x:x[:32])
departamentos['departamento']=departamentos['link1'].map(lambda x:x.replace('<a href="../', '').replace("</a></li>", "").replace('">', ",")).map(lambda x:x[33:])
departamentos1=departamentos[['link', 'departamento']]
The role to perform the loop by the department to extract the municipal relation relevant to each department is described next.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def func_mun(link, departamento):
html = requests.get("https://elecciones.registraduria.gov.co/pre_plebis_2016/"+link, verify=False).text
# We structure the data from the HTML files
soup = BeautifulSoup(html, "lxml")
muni=re.findall('<option value="../99PL/DPL["\w\s.>]+', str(soup))
municipios=pd.DataFrame()
municipios['link1']=muni
municipios['numeros']=municipios['link1'].map(lambda x:re.findall('[\d]+', str(x)))
municipios['indicativos']=municipios['numeros'].map(lambda x:len(x[1]))
municipios1=municipios[municipios['indicativos']>2]
municipios1['link']=municipios1['link1'].map(lambda x:x.replace('<option value="../', '')).map(lambda x:x[:32])
municipios1['municipio']=municipios1['link1'].map(lambda x:x.replace('<option value="../', '')).map(lambda x:x[34:])
municipios1['departamento']=departamento
return municipios1
This is the loop used to extract the municipal link related to each department.
1
2
3
4
5
6
total=pd.DataFrame()
for i in range(len(departamentos1)):
print("Iteracion",i)
total=total.append(func_mun(departamentos1['link'][i],departamentos1['departamento'][i] ))
total=total.reset_index(drop=True)
total1=total[['link', 'municipio', 'departamento']]
This function extracts the information of each municipality related to the number of voters in the decision of choice “yes” or “no” to the plebiscite and percentages.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
def busqueda(link):
html = requests.get("https://elecciones.registraduria.gov.co/pre_plebis_2016/"+link, verify=False).text
# We structure the data from the HTML files
soup = BeautifulSoup(html, "lxml")
a=re.findall('<div class="cajaDatosHeader"><b>[\w\s+%.-]+|<div class="cajaDatosBody"><span class="porcentajesCajas">[\w,+%.-]+|</span><br/><span class="descripcionCaja">[\w,\s%.-]+', str(soup))
ba=[]
ba.append(a[1])
bb=[]
bb.append(a[2])
m=re.search("([\w]+) de ([\w]+)", str(bb))
bc=[]
bc.append(a[4])
bd=[]
bd.append(a[5])
v1=re.findall("[\d.]+", str(bd))[0]
v2=re.findall("[\d.]+", str(bd))[1]
b=re.findall('<div class="skill-bar-percent pVotos">[\w,%()\s.]+|<div class="skill-bar-percent">[\w,()%\s.]+|<div class="skillbar-title"><span>[\w(),%\s.]+', str(soup))
be=[]
be.append(b[1])
app=re.findall("[\d,%.]+", str(be))
bf=[]
bf.append(b[2])
ap=re.search("[\d.]+", str(bf))
bg=[]
bg.append(b[4])
noapp=re.findall("[\d,%.]+", str(bg))
bh=[]
bh.append(b[5])
noap=re.search("[\d.]+", str(bh))
c=re.findall('<div class="contenido"><b>[\w\s.¡]+|</b><br/>[\d.]+', str(soup))
ca=[]
ca.append(c[1])
nu1=re.findall("[\d.]+", str(ca).replace("</b><br/>", ""))
cb=[]
cb.append(c[3])
nu2=re.findall("[\d.]+", str(cb))
cc=[]
cc.append(c[5])
nu3=re.findall("[\d.]+", str(cc))
base=pd.DataFrame()
base['link_real']=''
base['nombre_muni']=''
base['nombre_dep']=''
base['mesas_informadas%']=ba
base['mesas_informadas%']=base['mesas_informadas%'].map(lambda x:x.replace('<div class="cajaDatosBody"><span class="porcentajesCajas">',""))
base["mesas_informadas%"]=base["mesas_informadas%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
base['mesas_usadas']=m.group(1)
base['mesas_usadas']=base['mesas_usadas'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['mesas_disponibles']=m.group(2)
base['mesas_disponibles']=base['mesas_disponibles'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votantes%']=bc
base['votantes%']=base['votantes%'].map(lambda x:x.replace('<div class="cajaDatosBody"><span class="porcentajesCajas">',""))
base["votantes%"]=base["votantes%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
try:
base['votantes_cumplieron']=v1
base['votantes_cumplieron']=base['votantes_cumplieron'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votantes_habilidatos']=v2
base['votantes_habilidatos']=base['votantes_habilidatos'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
except:
base['votantes_cumplieron']=None
base['votantes_habilidatos']=None
base['apoya%']=app
base["apoya%"]=base["apoya%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
base['apoya#']=ap.group(0)
base['apoya#']=base['apoya#'].map(lambda x:str(x).replace(".","")).astype(int)
base['no_apoya%']=noapp
base["no_apoya%"]=base["no_apoya%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
base['no_apoya#']=noap.group(0)
base['no_apoya#']=base['no_apoya#'].map(lambda x:str(x).replace(".","")).astype(int)
base['votos_validos']=nu1
base['votos_validos']=base['votos_validos'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votos_no_marcados']=nu2
base['votos_no_marcados']=base['votos_no_marcados'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votos_anulados']=nu3
base["votos_anulados"]=base["votos_anulados"].map(lambda x:str(x).replace(".","")).astype(int)
return base
Finally, we generate the loop that makes the scraping by municipality and department to save the information in a DataFrame. That Dataframe is exported in CSV format to be manipulated in Google Data Studio.
1
2
3
4
5
6
7
8
9
10
base_total=pd.DataFrame()
for i in range(len(total1['link'])):
print("Iteracion:",i)
base=busqueda(total1['link'][i])
base_total=base_total.append(base)
base_total=base_total.reset_index(drop=True)
base_total['link_real']=total1['link']
base_total['nombre_muni']=total1['municipio']
base_total['nombre_dep']=total1['departamento']
base_total.to_csv("base_total1.csv", encoding='utf-8', index=False)
Once we have the database generated and refined, we go to Google Data Studio to build the graphs about the founded results.
This process can be replicated to whatever website has no renderization. In addition, the project has not to scope to make a deep analysis of the information because we have to review more factors such as demographics, politics, and economics.