
Descripción y Motivación
El plebiscito sobre los acuerdos de paz de Colombia de 2016 fue el mecanismo de refrendación para aprobar los acuerdos entre el gobierno de Colombia y la guerrilla de las Fuerzas Armadas Revolucionarias de Colombia (FARC). Las votaciones fueron programadas para el domingo 2 de octubre de 2016.
Esta fue la pregunta realizada en:
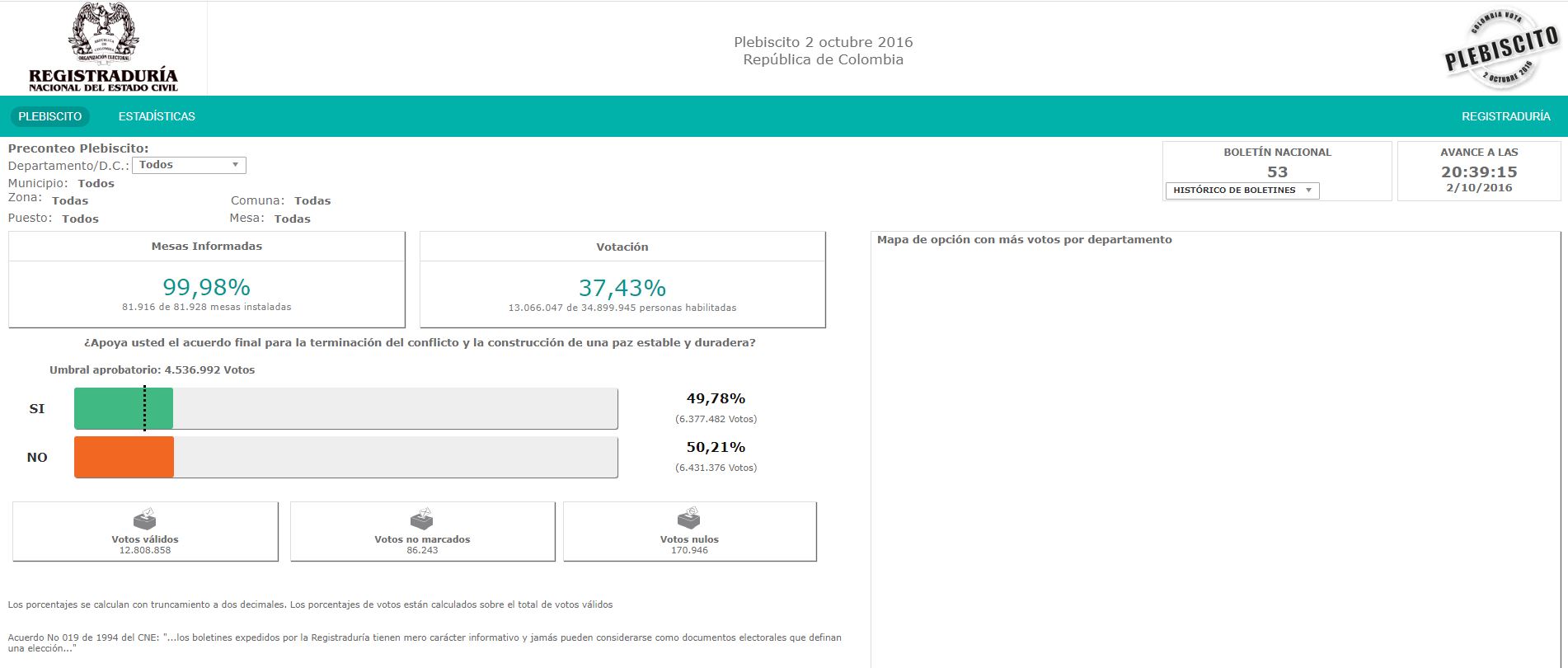
Dado lo anterior, el presente proyecto tiene como objetivo utilizar herramientas de Scraping a de Python para extraer dicha información a nivel de municipio y departamento para posteriormente mostrar dichos resultados en un panel de Google Data Studio.
Metodologías
El proceso de Scraping de la página de la Registraduría Nacional tiene las siguientes funciones:
- Realizar el scraping de la página principal del escrutinio de los resultados de la votación, esto para extraer el enlace de acceso a cada uno de los departamentos de Colombia en la votación. Luego de extraer la información por departamento, se extrae cada uno de los enlaces de los municipios relacionados a dicho departamento.
- Realizar el scraping de la página de cada Municipio para extraer los resultados de las votaciones como es el % de participación y de aprobación al plebiscito.
En este proceso, se extrajo la información de 1.186 municipios para 34 departamentos (incluidos consulados y Bogotá DC).
- Después de extraer la información, se genera el informe en Google Data Studio. La siguiente es el informe resultado del scrapping.
Proceso del Scraping
Se empieza importanto las librerias necesarias para la manipulación de los datos y la extracción en la página web. Para este fin, usaremos pandas, BeautifulSoup y requests, como se muestra a continuación:
1
2
3
4
5
6
7
8
import re
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import warnings
from requests.packages.urllib3.exceptions import InsecureRequestWarning
warnings.simplefilter('ignore',InsecureRequestWarning)
Una vez importadas las librerías, con la librería request traemos el código que se usa para la construcción de la página web con el fin de encontrar el link de la información del resultado del prebliscito por cada departamento.
1
2
3
4
5
6
html = requests.get("https://elecciones.registraduria.gov.co/pre_plebis_2016/99PL/DPLZZZZZZZZZZZZZZZZZ_L1.htm", verify=False).text
# estructurar datos a partir de archivos HTML
soup = BeautifulSoup(html, "lxml")
depa=re.findall('<a href="../99PL/DP["\w\s.>]+', str(soup))[2:-1]
departamentos=pd.DataFrame()
departamentos['link1']=depa
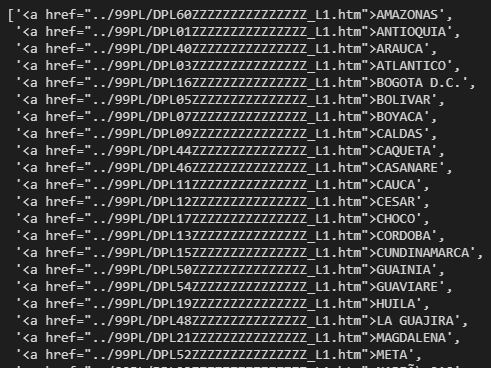
Luego con la lista de links por departamento, se realiza una limpieza de la información para generar el insumo con el cual se hará el segundo scrapping a nivel de municipio.
1
2
3
departamentos['link']=departamentos['link1'].map(lambda x:x.replace('<a href="../', '').replace("</a></li>", "").replace('">', ",")).map(lambda x:x[:32])
departamentos['departamento']=departamentos['link1'].map(lambda x:x.replace('<a href="../', '').replace("</a></li>", "").replace('">', ",")).map(lambda x:x[33:])
departamentos1=departamentos[['link', 'departamento']]
A continuación, se describe la función con la cual se realiza el loop por cada departamento para así extraer el link de cada municipio relacionado.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def func_mun(link, departamento):
html = requests.get("https://elecciones.registraduria.gov.co/pre_plebis_2016/"+link, verify=False).text
# estructurar datos a partir de archivos HTML
soup = BeautifulSoup(html, "lxml")
muni=re.findall('<option value="../99PL/DPL["\w\s.>]+', str(soup))
municipios=pd.DataFrame()
municipios['link1']=muni
municipios['numeros']=municipios['link1'].map(lambda x:re.findall('[\d]+', str(x)))
municipios['indicativos']=municipios['numeros'].map(lambda x:len(x[1]))
municipios1=municipios[municipios['indicativos']>2]
municipios1['link']=municipios1['link1'].map(lambda x:x.replace('<option value="../', '')).map(lambda x:x[:32])
municipios1['municipio']=municipios1['link1'].map(lambda x:x.replace('<option value="../', '')).map(lambda x:x[34:])
municipios1['departamento']=departamento
return municipios1
Este es el loop usado para extraer el link de cada municipio relacionado al departamento al cual pertenece.
1
2
3
4
5
6
total=pd.DataFrame()
for i in range(len(departamentos1)):
print("Iteracion",i)
total=total.append(func_mun(departamentos1['link'][i],departamentos1['departamento'][i] ))
total=total.reset_index(drop=True)
total1=total[['link', 'municipio', 'departamento']]
Esta función descrita a continuación extrae la información de cada municipio relacionada al número de votantes frente al si o al no en el plebiscito y medidas porcentuales.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
def busqueda(link):
html = requests.get("https://elecciones.registraduria.gov.co/pre_plebis_2016/"+link, verify=False).text
# estructurar datos a partir de archivos HTML
soup = BeautifulSoup(html, "lxml")
a=re.findall('<div class="cajaDatosHeader"><b>[\w\s+%.-]+|<div class="cajaDatosBody"><span class="porcentajesCajas">[\w,+%.-]+|</span><br/><span class="descripcionCaja">[\w,\s%.-]+', str(soup))
ba=[]
ba.append(a[1])
bb=[]
bb.append(a[2])
m=re.search("([\w]+) de ([\w]+)", str(bb))
bc=[]
bc.append(a[4])
bd=[]
bd.append(a[5])
v1=re.findall("[\d.]+", str(bd))[0]
v2=re.findall("[\d.]+", str(bd))[1]
b=re.findall('<div class="skill-bar-percent pVotos">[\w,%()\s.]+|<div class="skill-bar-percent">[\w,()%\s.]+|<div class="skillbar-title"><span>[\w(),%\s.]+', str(soup))
be=[]
be.append(b[1])
app=re.findall("[\d,%.]+", str(be))
bf=[]
bf.append(b[2])
ap=re.search("[\d.]+", str(bf))
bg=[]
bg.append(b[4])
noapp=re.findall("[\d,%.]+", str(bg))
bh=[]
bh.append(b[5])
noap=re.search("[\d.]+", str(bh))
c=re.findall('<div class="contenido"><b>[\w\s.¡]+|</b><br/>[\d.]+', str(soup))
ca=[]
ca.append(c[1])
nu1=re.findall("[\d.]+", str(ca).replace("</b><br/>", ""))
cb=[]
cb.append(c[3])
nu2=re.findall("[\d.]+", str(cb))
cc=[]
cc.append(c[5])
nu3=re.findall("[\d.]+", str(cc))
base=pd.DataFrame()
base['link_real']=''
base['nombre_muni']=''
base['nombre_dep']=''
base['mesas_informadas%']=ba
base['mesas_informadas%']=base['mesas_informadas%'].map(lambda x:x.replace('<div class="cajaDatosBody"><span class="porcentajesCajas">',""))
base["mesas_informadas%"]=base["mesas_informadas%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
base['mesas_usadas']=m.group(1)
base['mesas_usadas']=base['mesas_usadas'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['mesas_disponibles']=m.group(2)
base['mesas_disponibles']=base['mesas_disponibles'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votantes%']=bc
base['votantes%']=base['votantes%'].map(lambda x:x.replace('<div class="cajaDatosBody"><span class="porcentajesCajas">',""))
base["votantes%"]=base["votantes%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
try:
base['votantes_cumplieron']=v1
base['votantes_cumplieron']=base['votantes_cumplieron'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votantes_habilidatos']=v2
base['votantes_habilidatos']=base['votantes_habilidatos'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
except:
base['votantes_cumplieron']=None
base['votantes_habilidatos']=None
base['apoya%']=app
base["apoya%"]=base["apoya%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
base['apoya#']=ap.group(0)
base['apoya#']=base['apoya#'].map(lambda x:str(x).replace(".","")).astype(int)
base['no_apoya%']=noapp
base["no_apoya%"]=base["no_apoya%"].map(lambda x:str(x).replace("%","").replace(",",".")).astype(float)
base['no_apoya#']=noap.group(0)
base['no_apoya#']=base['no_apoya#'].map(lambda x:str(x).replace(".","")).astype(int)
base['votos_validos']=nu1
base['votos_validos']=base['votos_validos'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votos_no_marcados']=nu2
base['votos_no_marcados']=base['votos_no_marcados'].map(lambda x:str(x).replace("%","").replace(".","")).astype(int)
base['votos_anulados']=nu3
base["votos_anulados"]=base["votos_anulados"].map(lambda x:str(x).replace(".","")).astype(int)
return base
Finalmente, generamos el loop el cual hace el scraping para cada municipio por departamento y lo almacena en un dataframe, el cual es exportado en csv para poder ser manipulado en Google Data studio.
1
2
3
4
5
6
7
8
9
10
base_total=pd.DataFrame()
for i in range(len(total1['link'])):
print("Iteracion:",i)
base=busqueda(total1['link'][i])
base_total=base_total.append(base)
base_total=base_total.reset_index(drop=True)
base_total['link_real']=total1['link']
base_total['nombre_muni']=total1['municipio']
base_total['nombre_dep']=total1['departamento']
base_total.to_csv("base_total1.csv", encoding='utf-8', index=False)
Ya con la base generada y depurada, nos remitimos a Google data studio para realizar las gráficas para dicha información.
Este proceso realizado, es replicable a cualquier pagina web en donde no haya renderización. Así mismo, este proyecto no tiene el alcance de analizar a fondo la información ya que para esto hay que revisar más factores socio-demograficos y políticos y económicos.