According to McKinsey research, analysis of unstructured data—audio, text, and images—has strong future potential because of the volume stored and the relatively little investigation done so far.
This document presents an exploratory analysis of unstructured text extracted from PDFs, focusing on two key administrative instruments: decrees and resolutions issued between 2000 and May 2020. The exploratory work links macroeconomic and health indicators to surface inputs for future causal and correlation studies.
The following questions motivated the analysis:
- Over the last 20 years, several global health crises have occurred. Do the data reflect Colombia’s regulatory and control responses?
- Public health spending has fluctuated in recent years. Do the documents reflect that policy shift?
- As a country generates more income, social welfare and health coverage tend to rise. Do the data reflect coverage dynamics in Colombia?
- Can administrative acts since 2000 help explain the rise in affiliations under both the contributory and subsidized regimes?
1. Methodology
Scraping
Scraping is split into two notebooks: Scrapping_Decretos_MinSalud.ipynb for decrees and Scrapping_Resoluciones_MinSalud.ipynb for resolutions.
Each script has two stages:
- Fetch record counts, year, and year index to drive page scraping.
- 558 decrees — Decretos MinSalud
- 1,406 resolutions — Resoluciones MinSalud
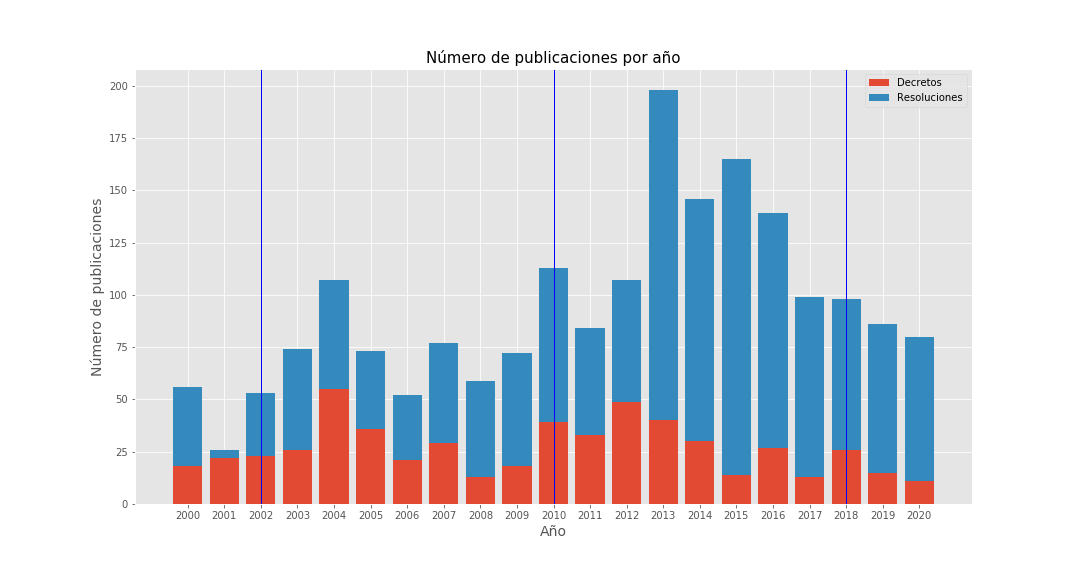
Vertical lines mark presidential transitions.
- With Selenium, simulate clicks on the ministry site to collect each document link for later download. Each notebook documents the flow with illustrative screenshots.
For this step you also need the ChromeDriver executable: Chromedriver for Selenium
The goal is to collect PDF URLs for all resolutions published on the ministry website and export them to Excel via a DataFrame.
PDF download and text transcription
Download and transcription are also split: Decree PDF download notebook and Resolution PDF download notebook.
Each script:
- Downloads every document listed on the ministry site using URLs from the scraping notebooks, via
urllib. - Transcribes PDFs to text and flags documents under 200 words—often scanned images—converting them to Word and re-exporting PDF when needed.
The output is a text DataFrame exported to Excel for analysis.
Consolidation and cleaning
Using Pandas, NLTK, scikit-learn, and Matplotlib, the transcribed corpora are cleaned and enriched. Four keyword dictionaries were built for:
- Epidemics
- Coverage
- Intervention
- Fraud
2. Analysis
Full analysis code: Analisis_textos.ipynb

Macro health indicators for Colombia came from:
- Health spending and physicians/nurses per 1,000 inhabitants — World Bank
- Coverage series — Ministry of Health
Coverage: 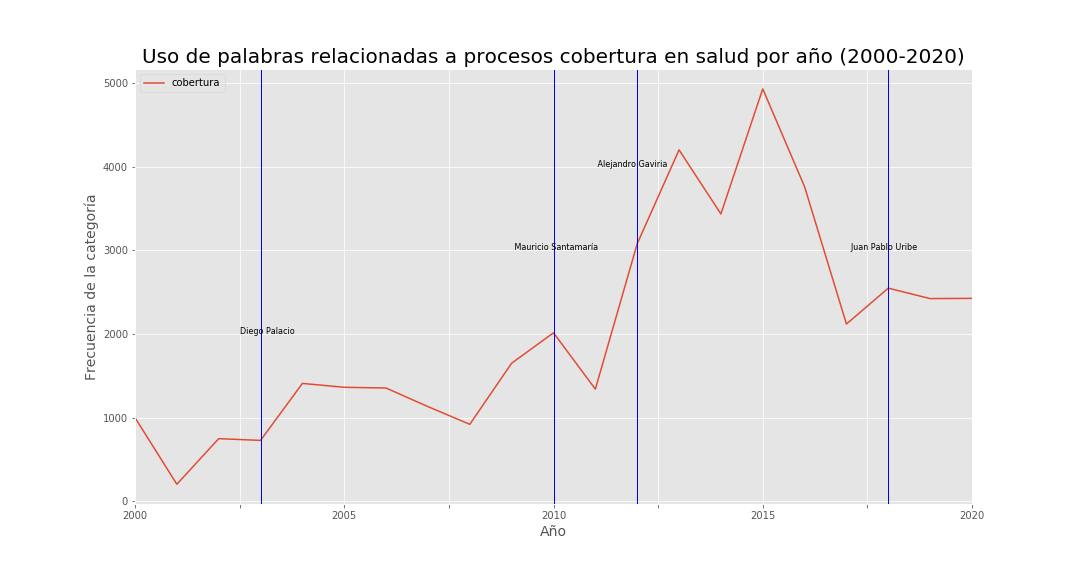 Figure 1.
Figure 1. 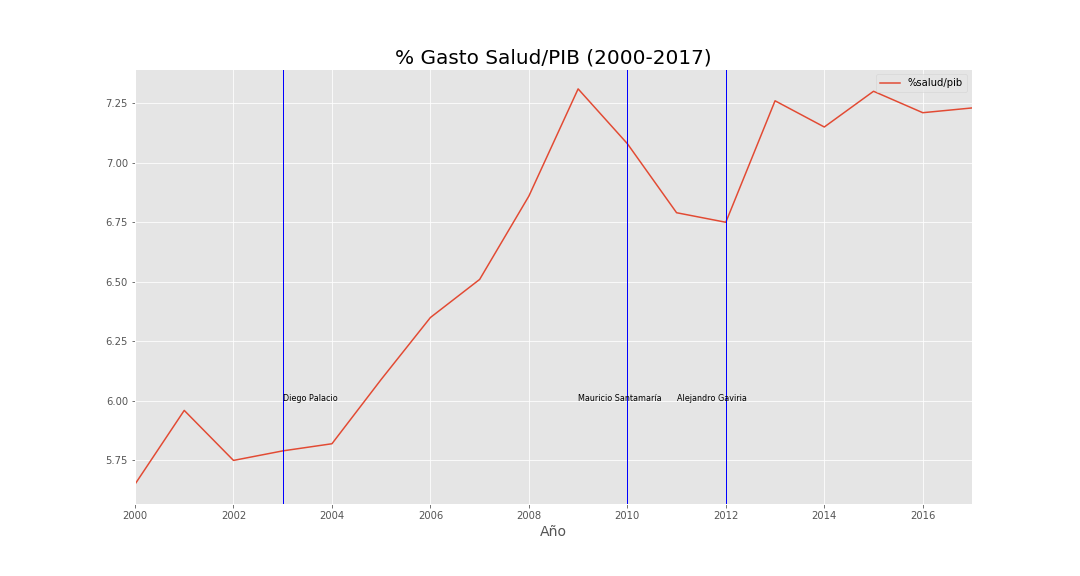 Figure 2.
Figure 2. 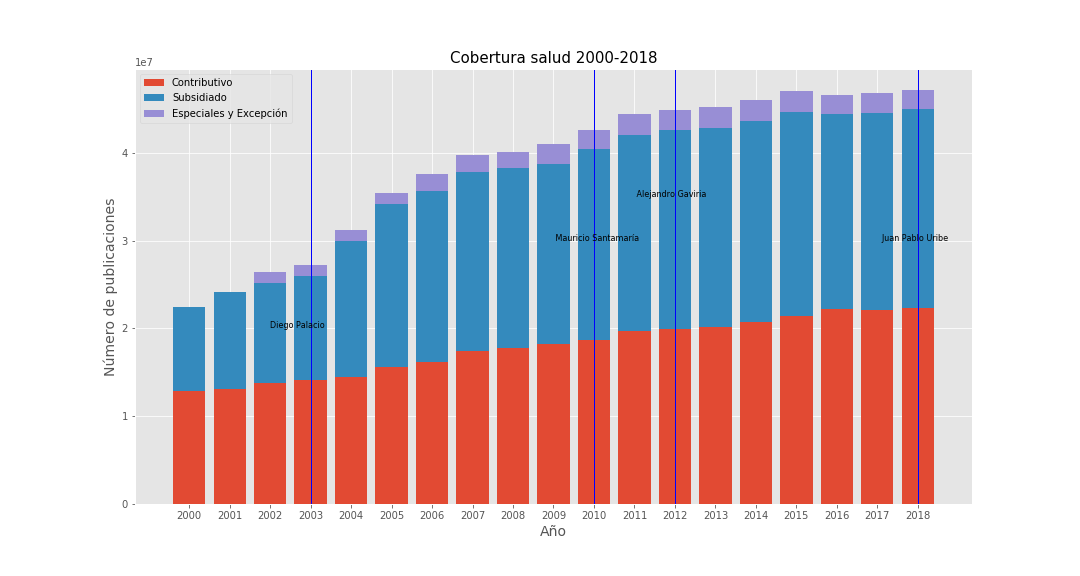 Figure 3.
Figure 3.
Each vertical line marks a change of Health Minister. Figure 1 shows a rising trend in coverage-related language, with a sharp peak under Alejandro Gaviria’s tenure—consistent with the coverage percentages in Figure 3 for both subsidized and contributory regimes.
Epidemics: 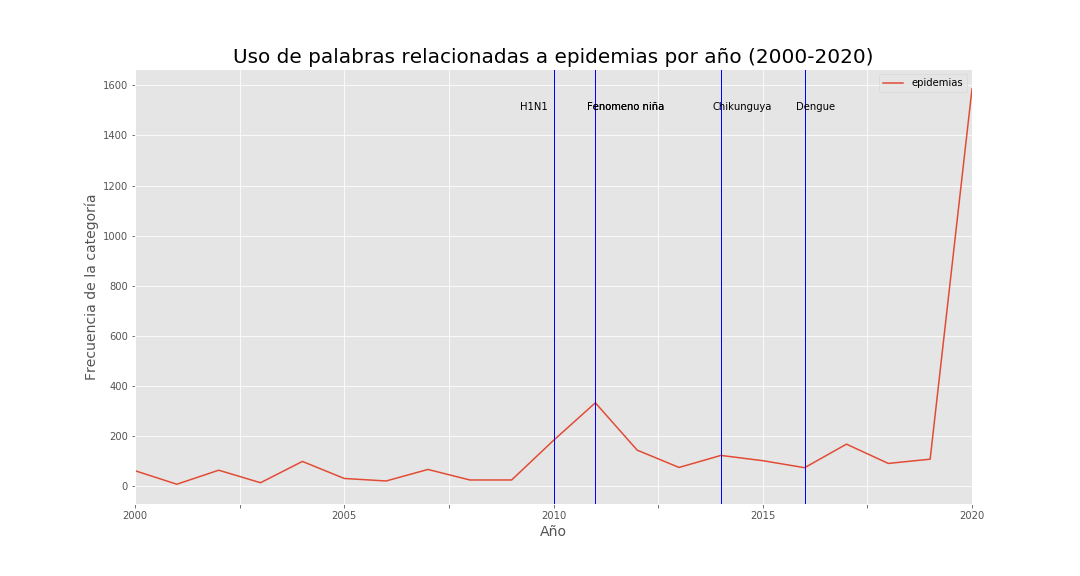 Figure 4.
Figure 4.
Interventions: 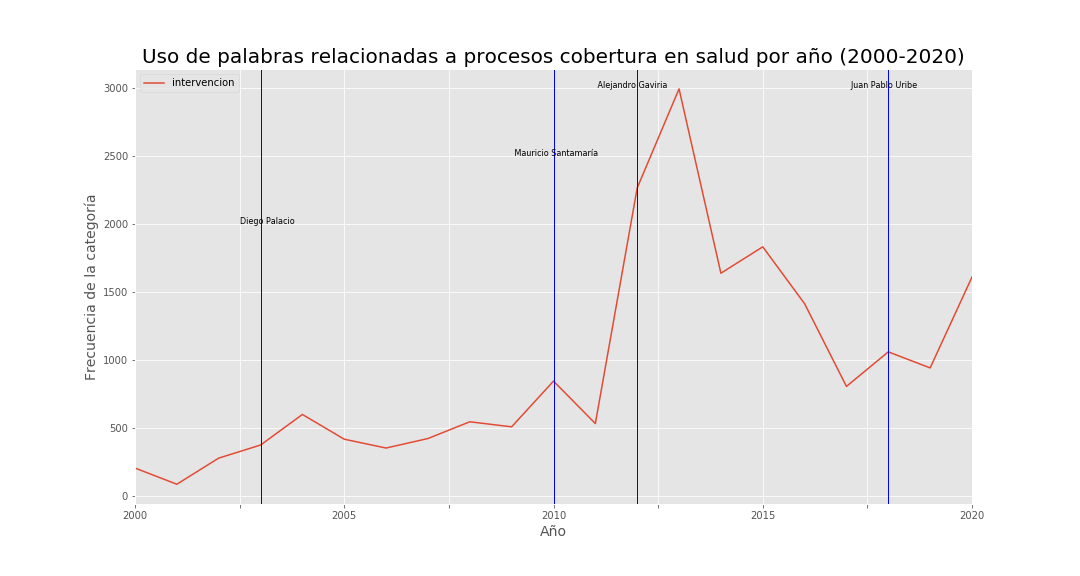 Figure 5.
Figure 5.
Fraud and litigation: 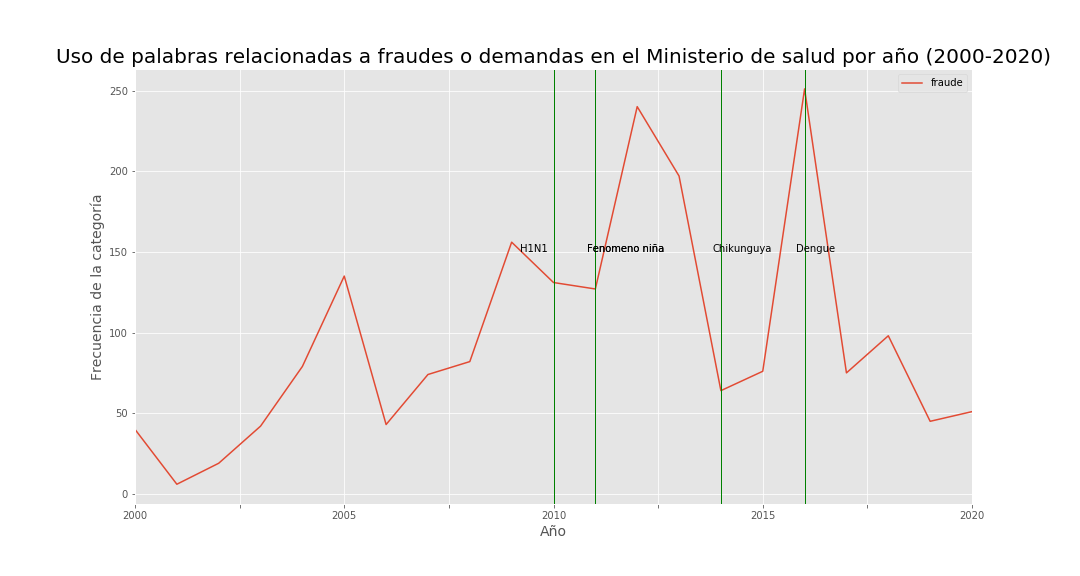 Figure 6.
Figure 6. 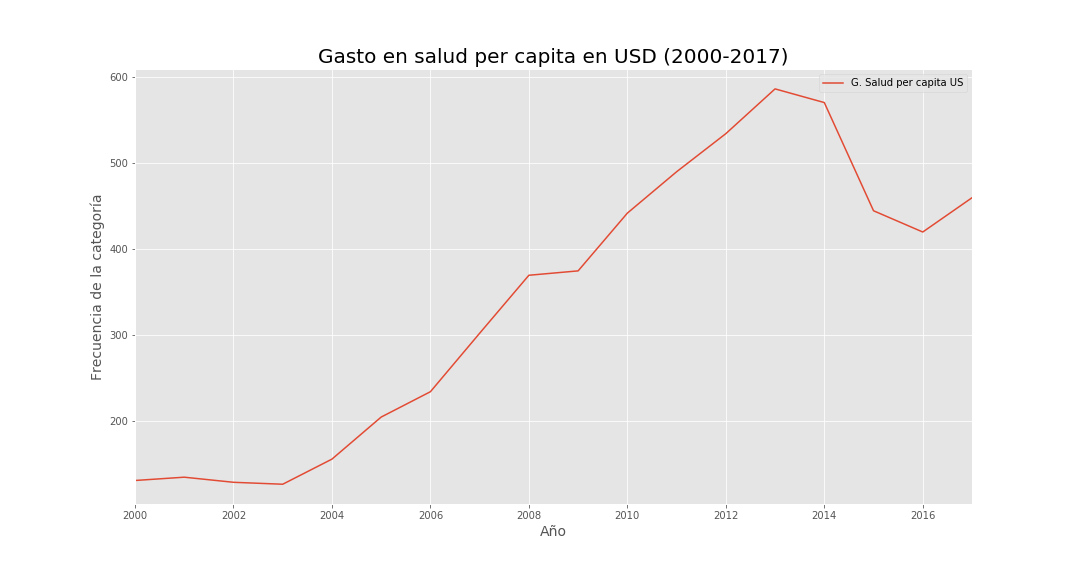 Figure 7.
Figure 7.
Despite rising coverage and document emphasis on that theme (Figures 1–3), decrees and resolutions also highlight interventions in public health institutions and fraud/litigation—especially after the niña phenomenon—suggesting sector inefficiencies and possible corruption. Figure 7 shows that although health spending as a share of GDP rose over 20 years, per-capita spending fell sharply in 2015.
Future work should investigate corruption and diversion of public funds.
Suggested follow-up research:
- Analyze correlations and external effects such as corruption in this regulatory body.
- Run causal analysis of inefficiency indicators at health centers by year and link them to intervention counts.
- Study pensioner and subsidized enrollment dynamics over time and test statistical significance against coverage growth.